 VIPC6资源网
VIPC6资源网
本套课程由CDA数据分析师和菜菜TsaiTsai主讲的:菜菜的机器学习sklearn课堂,课程官方售价499元,课程共11章节,共计39.2G,本套课程是机器学习和数据分析的很好的课程,文章底部附下载地址,如链接失效,可评论告知。
要学习这门课,你需要什么?
熟悉至少一门编程语言,最好是Python.
了解机器学习的基本概念。
对自己的承诺与能够付出的时间。
1.莱莱老师,真人出镜
一台电脑,一杯咖啡,带给你和老师面对面式的学习体验。
2.通俗讲解,快速入门
对机器学习经典算法进行原理和应用讲解,并结合python和sklearn库进行算法实现。
3.Python主导,突用高效
使用数据科学领域目前最主流语言Python及其建模库sklearn库作为课程核心工具。
4.案例为师,突战护航
基于真实数据集和项目案例,结合Python工具于机器学习算法完成整个案例实战。
5.持续更新,永欠有效
持续更新12期,逐步加入更多的算法和案例,课程永久有效。
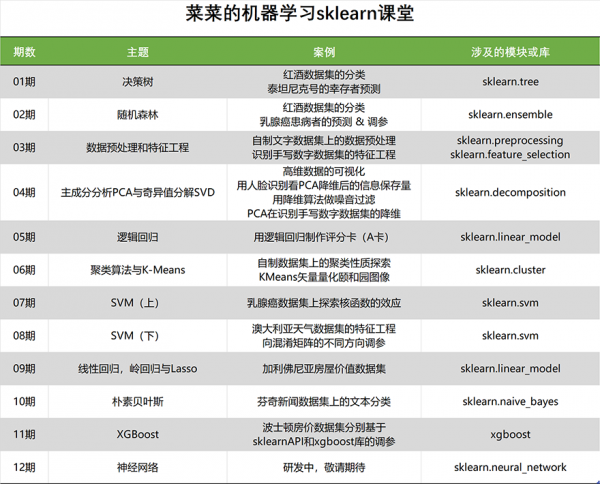
课程文件目录:菜菜的机器学习sklearn课堂(价值499) [39.2G]
1.引言,sklearn入门
2.决策树:概述
3.1分类树:参数criterion
3.2分类树:实现一棵树,随机性参数
3.3 分类树:剪枝参数调优(1)
3.4 分类树:剪枝参数调优(2)
3.5 分类树:重要属性和接口
4.1 回归树:参数,属性和接口
4.2 回归树:交叉验证 (1)
4.3 回归树:交叉验证(2)
4.4 回归树案例:用回归树拟合正弦曲线
5.1 案例:泰坦尼克号生存者预测 (1)
5.2 案例:泰坦尼克号生存者预测 (2)
5.3 案例:泰坦尼克号生存者预测 (3)
5.4 案例:泰坦尼克号生存者预测 (4)
02章 随机森林与医疗数据集调参
1 集成算法概述
2.1 随机森林分类器
2.2 参数boostrap & oob_score + 重要属性和接口
2.3 [选学] 袋装法的另一个必要条件
3.1 随机森林回归器
3.2 案例:用随机森林填补缺失值 (1)
3.3 案例:用随机森林填补缺失值 (2)
3.4 案例:用随机森林填补缺失值 (3)
3.5 案例:用随机森林填补缺失值 (4)
4. 机器学习中调参的基本思想
5.1. 案例:随机森林在乳腺癌数据上的调参 (1)
5.2 案例:随机森林在乳腺癌数据上的调参 (2)
03章 数据预处理与特征工程
0 概述 + 12期课纲
1.1 数据预处理1:数据归一化
1.2 数据预处理2:数据标准化
1.3 数据预处理3:缺失值 (1)
1.4 数据预处理4:缺失值 (2)
1.5 数据预处理5:处理分类型数据
1.6 数据预处理6:处理连续型数据
2.1 特征选择1:过滤法-方差过滤 (1)
2.2 特征选择2:过滤法-方差过滤 (2)
2.3 特征选择3:过滤法-卡方过滤
2.4 特征选择4:过滤法-F检验和互信息法 (1)
2.5 特征选择5:过滤法-互信息法(2) + 总结
2.6 特征选择6:嵌入法 (1)
2.7 特征选择7:嵌入法 (2)
2.8 特征选择8:包装法 + 总结
04章 降维算法PCA与手写数字识别
1 降维算法概述
2.1 降维究竟怎样实现?
2.2 参数 + 案例:高维数据的可视化 (1)
2.2 参数 + 案例:高维数据的可视化 (2)
2.3 PCA中的SVD,重要参数svd_solver
2.3 参数 + 案例:人脸识别中的components_应用.mp4
2.4 重要接口 + 案例1:用人脸识别看PCA降维后的信息保存量
2.4 重要接口 + 案例2:用PCA实现手写数字的噪音过滤
2.5 原理,流程,重要属性接口和参数的总结
3.1 案例:PCA实现784个特征的手写数字的降维 (1
3.2 案例:PCA实现784个特征的手写数字的降维 (2)
05章 逻辑回归和信用评分卡
0 前言
1.1 逻辑回归概述:名为“回归”的分类器
1.2 为什么需要逻辑回归
1.3 sklearn当中的逻辑回归
2.1.1 二元逻辑回归的损失函数
2.2.1 正则化:重要参数penalty & C
2.2.2 逻辑回归的特征工程 (1)
2.2.2 逻辑回归的特征工程 (2)
2.2.2 逻辑回归的特征工程 (3)
2.2.2 逻辑回归的特征工程 (4)
2.3.1 重要参数max_iter – 梯度下降求解逻辑回归的过程
2.3.2 梯度的概念与解惑
2.3.3 步长的概念与解惑
2.4 二元回归与多元回归:重要参数solver & multi_class
2.5 样本不均衡与参数class_weight
3.1 案例:评分卡与完整的模型开发流程
3.2.1~2 案例:评分卡 – 数据预处理(1) – 重复值与缺失值
3.2.3 案例:评分卡 – 数据预处理 (2) – 异常值
3.2.4 案例:评分卡 – 数据预处理 (3) – 标准化
3.2.5 案例:评分卡 – 数据预处理 (4) – 样本不均衡问题
3.2.6 案例:评分卡 – 数据预处理 (5) – 保存训练集和测试集数据
3.3 案例:评分卡 – 分箱 (1) – 概述与概念
3.3.1 案例:评分卡 – 分箱 (2) – 等频分箱 (1)
3.3.1 案例:评分卡 – 分箱 (3) – 等频分箱 (2)
3.3.2 案例:评分卡 – 分箱 (4) – 选学说明
3.3.3 案例:评分卡 – 分箱 (5) – 计算WOE与IV
3.3.4 案例:评分卡 – 分箱 (6) – 卡方检验、箱体合并、IV值等
3.3.5 案例:评分卡 – 分箱 (7) – 包装分箱函数
3.3.6 案例:评分卡 – 分箱 (8) – 包装判断分箱个数的函数
3.3.7 案例:评分卡 – 分箱 (9) – 对所有特征进行分箱
3.4 案例:评分卡 – 映射数据 (1)
3.4 案例:评分卡 – 映射数据 (2)
3.5 案例:评分卡 – 建模与模型验证
3.6 案例:评分卡 – 评分卡的输出和建立
06章 聚类算法与量化案例
0 概述
1.1 无监督学习概述,聚类vs分类
1.2 sklearn当中的聚类算法
2.1 Kmeans是如何工作的?
2.2 & 2.3 簇内平方和,时间复杂度
3.1.1 KMeans – 重要参数n_clusters
3.1.2 聚类算法的模型评估指标 (1)
3.1.2 聚类算法的模型评估指标 (2) – 轮廓系数
3.1.2 聚类算法的模型评估指标 (3) – CHI
3.1.3 案例:轮廓系数找最佳n_clusters (1)
3.1.3 案例:轮廓系数找最佳n_clusters (2)
3.1.3 案例:轮廓系数找最佳n_clusters (3)
3.2 重要参数init & random_state & n_init:初始质心怎么决定?
3.3 重要参数max_iter & tol:如何让聚类停下来?
3.5 重要属性与接口 & 函数k_means
4 案例:Kmeans做矢量量化 (1):案例背景
4 案例:Kmeans做矢量量化 (2)
4 案例:Kmeans做矢量量化 (3)
4 案例:Kmeans做矢量量化 (4)
07章 支持向量机与医疗数据集调参
0 本周要学习什么
1.1 支持向量机概述:最强大的机器学习算法
1.2 支持向量机是如何工作的 & sklearn中的SVM
2.1.1 线性SVC的损失函数 (1)
2.1.1 线性SVC的损失函数 (2)
2.1.2 函数间隔与几何间隔
2.1.3.1 损失函数的拉格朗日乘数形态
2.1.3.2 拉格朗日对偶函数 (1)
2.1.3.2 拉格朗日对偶函数 (2)
2.1.3.3 求解拉格朗日对偶函数极其后续过程
2.1.4 SVM求解可视化 (1):理解等高线函数contour
2.1.4 SVM求解可视化 (2):理解网格制作函数meshgrid与vstack
2.1.4 SVM求解可视化 (3):建模,绘制图像并包装函数
2.1.4 SVM求解可视化 (4):探索建立好的模型
2.1.4 SVM求解可视化(5):非线性数据集上的推广与3D可视化
2.1.4 SVM求解可视化(6):Jupyter Notebook中的3D交互功能
2.2.1 & 2.2.2 非线性SVM与核函数:重要参数kernel
2.2.3 案例:如何选取最佳核函数 (1)
2.2.3 案例:如何选取最佳核函数 (2)
2.2.4 案例:在乳腺癌数据集上探索核函数的性质
2.2.5 案例:在乳腺癌数据集上对核函数进行调参 (1)
2.2.5 案例:在乳腺癌数据集上对核函数进行调参 (2)
2.3.1 SVM在软间隔数据上的推广
2.3.2 重要参数C & 总结
08章 支持向量机与Kaggle案例:澳大利亚天气数据集
0 目录:本周将学习什么内容
1.1 简单复习支持向量机的基本原理
1.2 参数C的深入理解:多个支持向量存在的理由
1.3 二分类SVC中的样本不均衡问题
1.3 如何使用参数class_weight (1)
1.3 如何使用参数class_weight (2)
2 SVC的模型评估指标
2.1 混淆矩阵与准确率
2.1 样本不平衡的艺术(1):精确度Precision
2.1 样本不平衡的艺术(2):召回率Recall与F1 measure
2.1.3 对多数类样本的关怀:特异度Specificity和假正率
2.1.4 sklearn中的混淆矩阵
2.2 ROC曲线:Recall与假正率FPR的平衡
2.2.1 概率与阈值
2.2.2 SVM做概率预测
2.2.3 绘制ROC曲线 (1)
2.2.3 绘制ROC曲线 (2)
2.2.3 绘制ROC曲线 (3)
2.2.4 sklearn中的ROC曲线和AUC面积
2.2.5 利用ROC曲线求解最佳阈值
3 选学说明:使用SVC时的其他考虑
4 案例:预测明天是否会下雨 – 案例背景
4.1 案例:导库导数据,探索特征
4.2 案例:分集,优先处理标签
4.3.1 案例:描述性统计,处理异常值
4.3.2 案例:现实数据上的数据预处理 – 处理时间
4.3.3 案例:现实数据上的数据预处理 – 处理地点 (1)
4.3.3 案例:现实数据上的数据预处理 – 处理地点 (2)
4.3.3 案例:现实数据上的数据预处理 – 处理地点 (3)
4.3.3 案例:现实数据上的数据预处理 – 处理地点 (4)
4.3.4 案例:现实数据上的数据预处理 – 填补分类型变量的缺失值
4.3.5 案例:现实数据上的数据预处理 – 编码分类型变量
4.3.6 & 4.3.7 案例:现实数据集上的数据预处理:连续型变量
4.4 案例:建模与模型评估 (1)
4.4 案例:建模与模型评估 (2)
4.5.1 案例:模型调参:追求最高的recall
4.5.2 案例:模型调参:追求最高的精确度 (1)
4.5.2 案例:模型调参:追求最高的精确度 (2)
4.5.3 案例:模型调参:追求精确度与recall的平衡
4.6 SVM总结与结语
09章 回归大家族:线性,岭回归,Lasso,多项式
0 本周要学习什么.mp4
1 概述,sklearn中的线性回归大家族
2.1 多元线性回归的基本原理和损失函数
2.2 用最小二乘法求解多元线性回归的过程
2.3 多元线性回归的参数,属性及建模代码
3.1 回归类模型的评估指标:是否预测准确?
3.2 回归类模型的评估指标:是否拟合了足够的信息?
4.1 多重共线性:含义,数学,以及解决方案
4.2.1 岭回归处理多重共线性
4.2.2 sklearn中的岭回归:linear_model.Ridge
4.2.3 为岭回归选择最佳正则化参数
4.3.1 Lasso处理多重共线性
4.3.2 Lasso的核心作用:特征选择
4.3.3 Lasso选择最佳正则化参数
5.1.1 & 5.1.2 线性数据与非线性数据
5.1.3 线性vs非线性模型 (1):线性模型在非线性数据集上的表现
5.1.3 线性vs非线性模型 (2):拟合,效果与特点
5.2 离散化:帮助线性回归解决非线性问题
5.3.1 多项式对数据做了什么?
5.3.2 多项式回归提升模型表现
5.3.3 多项式回归的可解释性
5.3.4 多项式回归:线性还是非线性模型? + 本周结语
10章 朴素贝叶斯
0 本周要讲解的内容
1.1 为什么需要朴素贝叶斯
1.2 概率论基础 – 贝叶斯理论等式
1.2.1 瓢虫冬眠:理解条件概率 (1)
1.2.1 瓢虫冬眠:理解条件概率 (2)
1.2.1 瓢虫冬眠:理解条件概率 (3)
1.2.2 贝叶斯的性质与最大后验估计
1.2.3 汉堡称重:连续型变量的概率估计 (1)
1.2.3 汉堡称重:连续型变量的概率估计 (2)
1.3 sklearn中的朴素贝叶斯
2.1.1 认识高斯朴素贝叶斯
2.1.2 高斯朴素贝叶斯擅长的数据集
2.1.3 探索贝叶斯 – 拟合中的特性与运行速度 (1)
2.1.3 探索贝叶斯 – 拟合中的特性与运行速度 (2) – 代码讲解 (1)
2.1.3 探索贝叶斯 – 拟合中的特性与运行速度 (3) – 代码讲解 (2)
2.1.3 探索贝叶斯 – 拟合中的特性与运行速度 (4) – 分析与结论
2.2.1 概率类模型的评估指标 (1) – 布里尔分数
2.2.1 概率类模型的评估指标 (2) – 布里尔分数可视化
2.2.2 概率类模型的评估指标 (3) – 对数损失Logloss
2.2.3 概率类模型的评估指标 (4) – 可靠性曲线 (1)
2.2.3 概率类模型的评估指标 (5) – 可靠性曲线 (2)
2.2.4 概率类模型的评估指标 (6) – 概率分布直方图
2.2.5 概率类模型的评估指标 (7) – 概率校准 (1)
2.2.5 概率类模型的评估指标 (8) – 概率校准 (2)
2.3.1 多项式朴素贝叶斯 (1) – 认识多项式朴素贝叶斯
2.3.1 多项式朴素贝叶斯 (2) – 数学原理
2.3.1 多项式朴素贝叶斯 (3) – sklearn中的类与参数
2.3.1 多项式朴素贝叶斯 (4) – 来构造一个分类器吧
2.3.2 伯努利朴素贝叶斯 (1) – 认识伯努利朴素贝叶斯
2.3.2 伯努利朴素贝叶斯 (2) – sklearn中的类与参数
2.3.2 伯努利朴素贝叶斯 (3) – 构造一个分类器
2.3.3 探索贝叶斯 – 朴素贝叶斯的样本不均衡问题
2.3.4 补集朴素贝叶斯 – 补集朴素贝叶斯的原理 (1)
2.3.4 补集朴素贝叶斯 – 补集朴素贝叶斯的原理 (2)
2.3.4 补集朴素贝叶斯 – 处理样本不均衡问题
3.1.1 案例:贝叶斯做文本分类 (1) – 单词计数向量技术
3.1.1 案例:贝叶斯做文本分类 (2) – 单词计数向量的问题
3.1.2 案例:贝叶斯做文本分类 (3) – TF-IDF技术
3.2 案例:贝叶斯做文本分类 (4) – 探索和提取文本数据
3.3 案例:贝叶斯做文本分类 (5) – 使用TF-IDF编码文本数据
3.4 案例:贝叶斯做文本分类 (6) – 算法应用与概率校准
11章 XGBoost
0 本周要学习什么
1 XGBoost前瞻:安装xgboost,xgboost库与skleanAPI
2.1 梯度提升树(1):集成算法回顾,重要参数n_estimators
2.1 梯度提升树(2):参数n_estimators下的建模
2.1 梯度提升树(3):参数n_estimators的学习曲线
2.1 梯度提升树(4):基于方差-偏差困境改进的学习曲线
2.2 梯度提升树(5):控制有放回随机抽样,参数subsample
2.3 梯度提升树(6):迭代决策树:重要参数eta
2.3 梯度提升树(7):迭代决策树:重要参数eta
3.1 XGBoost的智慧 (1):选择弱评估器:重要参数booster
3.2 XGBoost的智慧 (2):XGBoost的目标函数,使用xgboost库建模
3.3 XGBoost的智慧 (3):求解XGBoost的目标函数 – 推导过程
3.3 XGBoost的智慧 (4):XGboost的目标函数 – 泰勒展开相关问题
3.4 XGBoost的智慧 (5):参数化决策树,正则化参数lambda与alpha
3.5 XGBoost的智慧 (6):建立目标函数与树结构的直接联系
3.5 XGBoost的智慧 (7):最优树结构,求解w和T
3.6 XGBoost的智慧 (8):贪婪算法求解最优树
3.7 XGBoost的智慧 (9):让树停止生长:参数gamma与工具xgb.cv
4.1 XGBoost应用 (1):减轻过拟合:XGBoost中的剪枝参数
4.1 XGBoost应用 (2):使用xgb.cv进行剪枝参数的调参
4.2 XGBoost应用 (3):使用pickle保存和调用训练好的XGB模型
4.2 XGBoost应用 (4):使用joblib保存和调用训练好的XGB模型
4.3 XGBoost应用 (5):XGB分类中的样本不平衡问题 – sklearnAPI
4.3 XGBoost应用 (6):XGB分类中的样本不平衡问题 – xgboost库
4.4 XGBoost应用 (7):XGB应用中的其他问题
课件
01 决策树课件数据源码
决策树 案例部分源码-checkpoint
决策树 原理部分源码-checkpoint
决策树 案例部分源码
决策树 原理部分源码
决策树 full version
决策树原理更新
data
Taitanic data
test
Tree
Tree
Tree【瑞客论坛 www.ruike1
02随机森林
随机森林 full version
digit recognizor
Record
sample_submission
test
train
03数据预处理和特征工程
record-checkpoint
数据预处理和特征工程 – 数据
数据预处理与特征工程 full version
数据预处理与特征工程 full version
digit recognizor
Narrativedata
record
04主成分分析PCA与奇异值分解SVD
Record-checkpoint
record2-checkpoint
降维算法 full version
降维算法 full version
digit recognizor
Record
record2
05逻辑回归与评分卡
逻辑回归-checkpoint
评分卡模型-checkpoint
逻辑回归 full version
逻辑回归 full version
逻辑回归
逻辑回归课件 + 数据
评分卡模型
model_data
rankingcard
ScoreData
vali_data
06聚类算法Kmeans
聚类算法与Kmeans-checkpoint
聚类算法与Kmeans
聚类算法与Kmeans代码
聚类算法KMeans EDU version
07支持向量机上
SVM1-checkpoint
Record
SVM (上) full version
SVM (上) full version
SVM1
08支持向量机下
SVM 2 – 理论部分源码-checkpoint
Cityclimate
cityll
samplecity
SVM (下) – 源码
SVM (下) full version
SVM (下) full version
SVM 2 – 案例部分源码
SVM 2 – 理论部分源码
SVM数据
weather
weatherAUS5000
09回归大家族:线性回归,岭回归,Lasso与多项式回归
线性回归 – 代码
线性回归 课件 + 代码
线性回归大家族 full version
010朴素贝叶斯
010朴素贝叶斯
朴素贝叶斯 full version
Naive Bayes源码
011XGBoost
Untitled-checkpoint
xgboost code-checkpoint
xgboost 代码 + 课件
xgboost code
XGBoost full version
参考书1
参考书2
参考书3
开始机器学习之前:配置开发环境
下载地址:
VIP会员免C币下载,如链接失效,可评论告知。
2020-12-7 更新下载链接。
解压失败是什么问题?
换个解压软件试试 另外不要在线解压
问题解决了吗,我也是这个问题
你好 分卷压缩包 需要全部下载到本地之后再解压,具体可参考该页面说明:https://www.vipc6.com/download_info
文件总共大小9.45GB,这个是完整的了吗? 解压仍然失败。使用的是mac
你好,完整版是39.2G,分为4个卷压缩的,需要全部下载后解压。